A palavra e as “coisas”: como montar a sua lista de termos para coleta de dados em redes sociais
5 de outubro de 2020
por Fabio Malini
como os termos de busca influenciam a pesquisa dirigida por dados de redes sociais e revelam o viés do pesquisador
.
Ao iniciar um projeto de pesquisa dirigida pela coleta e manejo de dados digitais massivos em plataformas de redes sociais (Twitter, Facebook, Instagram, Youtube etc), o primeiro passo a se dar é definir os termos (queries) que serão buscados através de consultas ans Interfaces de Programação de Aplicações (APIs) dessas plataformas. Em geral, são palavras ou expressões que compostas com uso de operadores booleanos básicos, como and, or, not e uso do “entre aspas” para encontrar conteúdos contendo expressões específicas.
Assim, por exemplo, se o seu programa de coleta de dados requisitar à API do Facebook os termos vacina and covid, este entenderá que a requisição tem a função de interseção, retornando assim apenas as mensagens contendo os dois termos, isto é, um post com a mensagem “Brasil vai produzir vacina contra covid” fará parte da base de dados retornada pela API, porém, a frase “Brasil se nega a produzir vacina contra coronavírus”, não, pois só a primeira os termos vacina e covid estão presentes numa frase. Agora, se a consulta solicitasse brasil and produzir, daí ambas mensagens seriam entregues para o pesquisador.
Quando um termo possui um significado amplo e assertivo (como covid, sem ambiguidade sobre o tema que se trata), a decisão de sua adoção ajuda na captura da diversidade de visões que será extraída nas redes sociais. Já quando se trata de uma controvérsia (a volta às aulas durante a pandemia de covid-19, por exemplo), cabe o pesquisador recolher o máximo de termos que conduzam a declarações dos mais distintos grupos que tratam do assunto nas redes sociais. Uma escolha de termos feita às pressas pode ocultar informações preciosas contidas em diferentes bolhas que não usam o termo escolhido pelo pesquisador, que, ao não incorporá-las à coleção final de dados (dataset), ora pela inexperiência, ora pelo viés ideológico, perderá a oportunidade de registrar o debate mais denso, uma conversação mais diversa e um fluxo de contraditório mais tenso nas redes.
desdobrar as palavras-multiverso
Para obter um dataset vasto em termos de diversidade discursiva, o primeiro procedimento é aguardar que acontecimento foco do estudo vá se desdobrando. Pensado como um momento discursivo (Moirand, 2007), o acontecimento em rede social precisa de um prazo mais alargado do que o tempo acelerado das redes para que diferentes perspectivas e diferentes atores se manifestem sobre ele. É muito comum quando um fato de grande importância irrompe que existam declarações de alta popularidade, mas que terão seus contrapontos conforme o tempo passa (isso pode levar minutos ou dias). Assim, o momento discursivo é de médio prazo (a novidade dura em torno de 36 horas) e com banda larga (com múltiplos participantes), acumulando uma abundante produção de mensagens, que decresce proporcionalmente à redução do número de novos fatos ou declarações de impactos sobre o acontecimento sob monitoramento.
É essa espera que permitirá ao pesquisador identificar as palavras-evento (Moirand, 2007), os termos ou expressões que nomeiam um episódio. Em redes sociais, os participantes rotulam um evento através de hashtags, que agregam a diversidade e variações de declarações sobre o acontecimento. Assim, #VemPraRua, #VidasNegrasImportam, #TchauQuerida ou #LulaLivre titulam fatos, servindo de índice para se memorizar e se conectar a diferentes modos de ler a realidade sobre cada um dessas ocorrências. Um dos principais papéis do cientista de dados é preservar exatamente essa memória multifacetada que as palavras-evento provocam através de compartilhamentos de links, textos, declarações, vídeos, imagens, enfim, todo um arquivo multimodal de discursos.
Mas buscar dados completos sobre um evento não se restringe apenas à coleta de hashtags, até porque muitas destas são programadas por equipes de comunicação e marketing de organizações sociais, corporações ou instituições governamentais para exatamente enquadrar a realidade de um acontecimento a uma narrativa que conduza o pesquisador a uma interpretação favorável a determinado grupo social (Malini, 2020). No tempo do desdobramento do fato, que é o tempo de vigília do pesquisa, é preciso também rastrear as palavras-argumento, entidades que, na acepção de Moirand (2007), operam os conceitos-chave da fundamentação de certo discurso. Assim, “passe livre”, “racismo estrutural”, “impeachment” ou “guerra jurídica” (lawfare) funcionam respectivamente como expressões que mobilizam cada uma das hashtags citadas anteriormente, sendo utilizadas pelos participantes para dar consistência ao acontecimento, enriquecendo as hashtags com perspectivas e debates que ampliam o contexto, disputam sentidos, ativam as audiências no sentido de engajá-las em argumentos em prol de certo posicionamento na arena pública ou mesmo saturam a mente dos públicos de desinformação ou confusão para esvaziar uma determinada argumentação online.
Aliada às marcações identitárias das palavras-evento e das palavras-argumento, há o que eu denomino de palavras–multiverso, por se tratarem de termos e expressões que abrigam uma vastidão de tópicos e posicionamentos, impossibilitando que sejam nominadas como pertencente a um grupo social, senão cimentada na própria cotidianidade, e por isso quase sempre requeridas como um semântica capaz de mediar a participação na arena pública discursiva das redes, por continuamente evocar e notificar situações novas que demandam debates, anúncios, pronunciamentos e denúncias. Esse rol de palavras é onde reside a coloquialidade da vida social em rede. Em termos práticos, por exemplo, isso é comum quando temos de lidar com o desafio de extrair dados sobre o impacto das falas públicas de um político. Há a palavra-evento (#Debate2020), mas temos de reunir as palavras-multiverso (Bolsonaro, Lula, Ciro), que em certas situações podem ser ainda mais opacas (candidato, presidente, opositor, aliado, concorrente), mas que são redigidas pelos participantes de redes sociais como estratégia de não projeção identitária (ser parte de uma hashtag), servindo como gatilho para a produção de comentário sobre aquilo que se observa. Ou, em raros casos, como estratégia não serem capturados pelas máquinas de monitoramento de dados na rede. Essas palavras só farão sentido se o cientista de dados coletá-las no período em que está acontecendo o fato, capturando o contexto discursivo que originou o posicionamento desses comentários. Durante um debate eleitoral, será assertivo que a palavra ‘candidato’, redigida nas redes sociais, se refira àqueles indivíduos que estão a discutir suas propostas de governo entre si na tevê ou num canal de videostreaming. Dois dias depois do fato, o mesmo termo estará vinculado às eleições, mas dissociado do debate televisivo.
Outro tema político corriqueiro que as palavras-multiverso são úteis é a pesquisa sobre o ativismo. Em geral, estas são baseadas em hashtags (#BrequeDosApp, #BlackLivesMatter, #FridayForFuture, #VemPraRua, # etc) para marcar o movimento nas redes. No ativismo, a hashtag serve para um triplo propósito. Primeiro, como um teaser. Ou seja, possui poder convocatório, antecipando a ideia e o modo de ocupação das ruas que buscam os seus organizadores, entrando publicamente na agenda dos fatos relevantes da arena política como uma tática para chamar a atenção de jornalistas, produzir tensão prévia em antagonistas e engajar paulatinamente influenciadores digitais como aliados do movimento. Segundo, possui função narrativa, à medida que os ativistas estão organizados para associar a hashtag aos conteúdos multimídia gerados por eles com exclusividade durante o dia da manifestação, material que será publicado em tempo real nos canais oficiais do protesto nas redes sociais, mantendo assim o controle das histórias e do ângulo que os manifestante buscam realçar em diferentes timelines, educando a audiência em torno de suas reivindicações. E, por fim, visa produzir uma linguagem própria, envelopando os atos como uma estética, tanto verbal, quanto visual, para disputar a atenção da opinião pública a ponto de pautá-la com uma discursividade que seja facilmente incorporada por perfis fora das bolhas ideológicas contra e a favor do movimento. Por isso que toda vez que há movimentos sociais nas rua, cabe ao pesquisador coletar nas APIs os termos ‘protesto’, ‘manifestante’, ‘manifestação’, ‘manifestações’, e assim incorporar no dataset vozes que não requerem uma rotulação identitária dessas bolhas, ao contrário, estão continuamente avaliando as ações desencadeadas pelos ativistas.
Um exemplo pra ilustrar. No dia 01 de junho de 2020, movimentos antifascistas ocuparam as ruas no Brasil para protestar contra a negligência do governo Bolsonaro em combater a pandemia de covid-19. A hashtag que intitulava o evento era #AntifasPelaDemocracia. Era o primeiro protesto a tomar as ruas durante o período de alta propagação da doença no país. No fim do dia, de modo surpreendentemente, o evento saiu das mãos da narrativa dos ativistas e acabou por provocar um processo de alta viralização não apenas das imagens exclusivas do protesto, mas sobretudo por um fato inusitado: a bandeira antifascista tornou-se um template que ia alterando conforme a identidade de cada grupo online. Assim, havia bandeira de artistas antifacistas, administradores antifascistas, professores antifascistas, ciência da computação antifascistas, indígenas antifascistas, enfim, uma memetização da bandeira antifa que unia políticos como Boulos e celebridades como a Xuxa.
Dado a amplitude da carga viral sobre o tema, se o pesquisador poderia extraísse somente as mensagens com a hashtag #AntifasPelaDemocracia, traçaria o perfil dos influenciadores do movimento que participavam e se engajavam na difusão dos registros dos atos. Seriam 29 mil mensagens mapeadas no Twitter, 23.570 usuários publicando ou replicando-as. Adicionando, por exemplo, as palavras protesto, manifestação, democracia, manifestantes, avenida paulista, antifascista, o pesquisador conseguiria alcançar os mais de 2 milhões de posts publicados sobre os atos e a memetização das bandeiras, revelando a alta densidade de influenciadores e detratores do movimento. As duas estratégias terminariam em dois grafos de interações entre atores, baseados em retweets (compartilhamentos), totalmente diferentes, como se vê nos grafos da Figura abaixo. O primeiro, apenas focado na hashtag #AntifasPelaDemocracia; o segundo, incorporando as palavras-multiverso acima citadas.
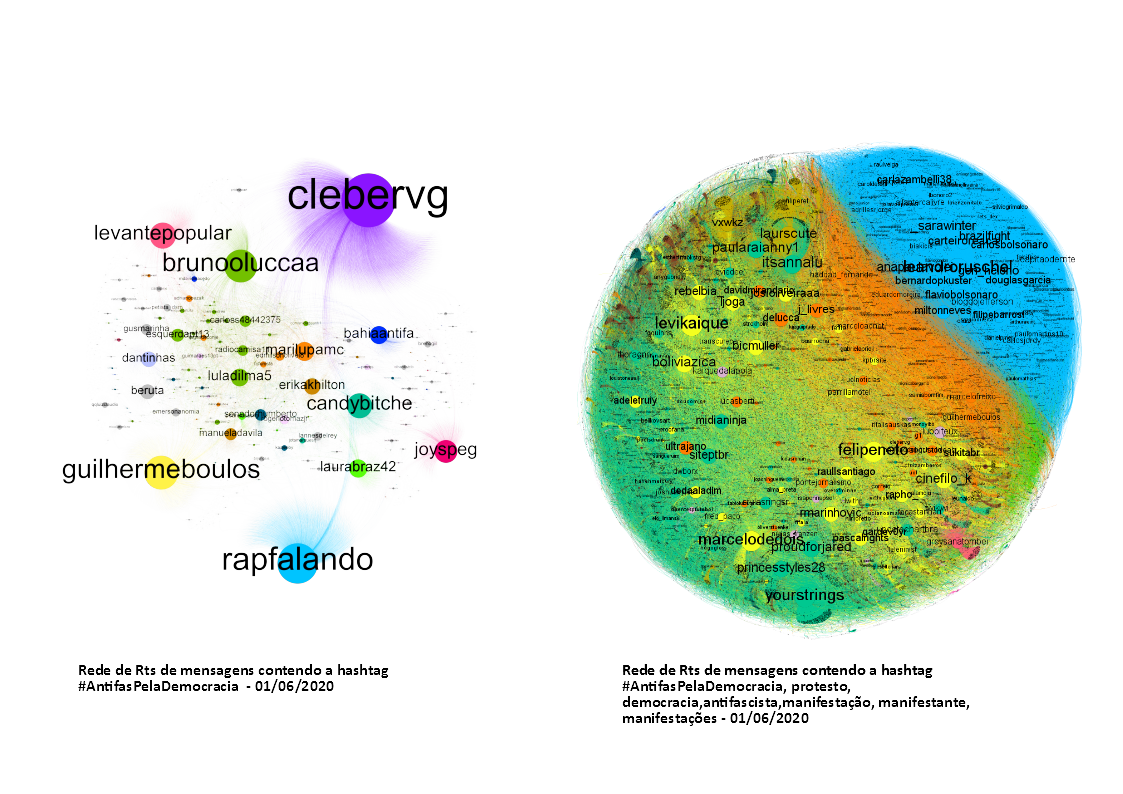
O empenho de incluir palavras-multiverso no dataset, no meu entender, é uma estratégia fundamental de apreensão do panorama discursivo em rede, abrigando visões que escapam ao efeito de câmara de eco que as redes sociais produzem, podendo assim controlar um duplo viés: o do analista, que tende a escolher os termos que são mais vivos na sua memória, ou por influência do hype midiático, ou por sua visão política; e o viés das plataformas digitais, cuja tendência é de retroalimentar o sistema de crenças dos grupos sociais conectados a elas, dando visibilidade a hashtags, personalidades e termos discussões mais frequentemente expressas (em alguns casos, até usando bots para isso).
As palavras-multiverso possuem as marcas da ordinariedade, revelando relações mais fragmentadas entre atores, pois não são associadas a uma crença, ideologia política, a uma identidade ou preferência de consumo. Um bom exemplo da importância das palavras-multiverso disso é a pandemia de covid-19 que atravessa o mundo. O contágio global do coronavírus é marcado pela profusão de hashtags e novas expressões em diferentes idiomas, mas o que agrega maior volume de menções são termos amplos como covid, coronavírus e vírus, incapazes de rotular um evento ou argumento específicos, senão de amplificar uma variedade trama de significações que a doença provoca no planeta.
Duas observações adicionais sobre termos de coletas em APIs. A primeira é cuidado com termos ambíguos sem contexto que os ajude serem desambiguados. TPor exemplo, o estudioso sobre futebol e redes sociais pode querer analisar o comportamento dos torcedores do Vitória da Bahia. Contudo, a palavra Vitória pode significar inúmeros sentidos no período de sete dias de coleta, implicando o oposto de derrota, ou a capital do Espírito Santo ou o nome de uma pessoa. Mas se o pesquisador decidir extrair o termo ‘vitória’ durante um jogo televisionado do time baiano é bem possível que a palavra retornará mensagens sobre a performance da equipe rubro-negra de Salvador.
Há, por fim, termos que são entidades lexicais que advêm da linguagem das redes sociais. É o caso do link. No Twitter, por exemplo, toda imagem ou vídeo tem um endereço. Exemplo: <https://twitter.com/i/status/1313107130023587845>. O pesquisador pode adotar esse link como um termo de busca, fazendo que a API retorne apenas as mensagens que contenham o link. Outra dica: é muito comum traçar o impacto de uma mensagem. Em plataformas como Youtube, o acesso a comentários é bem facilitado pela API, basta saber o ID do vídeo, que a API retornará os comentários sobre ele. Enfim, as artimanhas de coletas sobre personalidades podem se dar não apenas na coleta do nome da pessoa (Bolsonaro), mas usar nome do perfil (jairbolsonaro) como uma query, isto permite recuperar todos os replies e menções ao presidente no Twitter durante certo período de tempo, o que abre a possibilidade de análise heterofílicas sobre o discurso dele.
Enfim, reunir seus termos de busca requererá um cálculo baseado no desdobramento do tempo do acontecimento, conjugando as palavras-evento, argumento e multiverso, o que abrirá um desafio ao pesquisador: lidar com a fragmentação da conversação, aquilo que Gabriel Tarde chamava de pluralidade e variações que denotam o mundo vivo.
Referências Bibliográficas:
Malini, Fabio. Quando tudo parecia ser tão distante daqui: a eclosão das narrativas sobre covid-19. Disponível em: <https://medium.com/@fabiomalini/quando-tudo-parecia-ser-t%C3%A3o-distante-daqui-a-eclos%C3%A3o-das-narrativas-sobre-covid-19-23ef531b1be1>
Moirand, Sophie. Les discours de la presse quotidienne : observer, analyser, comprendre. Paris: Presses Universitaires de France, 2007
Tarde, Gabriel. A opinião e as massas. São Paulo: Martins Fontes, 1992
Comentários